Lesson 22: BERT, GPT, T5 and BART

BERT, GPT, T5 and BART
The transformer architecture was originally designed for sequence-to-sequence tasks such as machine translation. However, the encoder and decoder blocks were soon adapted as standalone models. Transformers are typically pretrained using self-supervised (unsupervised) learning and fine-tuned for specific tasked using supervised learning. There are hundreds of different transformer models but most of them are either encoder only, decoder only or encoder-decoder models.
Encoder Only
An encoder only transformer is a model consisting of encoder stacks and focuses solely on converting or encoding an input sequences of text into a meaningful numerical representations. Encoder only models are suitable for producing token embeddings that capture complex relationships in input sequences. These embeddings can be used downstream for natural language understanding tasks such as text classification. BERT is an example of encoder only model.
Encoder only models can be viewed as autoencoders because they learn a representation (an encoding) for each input sequence with a training objective of reconstructing masked tokens given the surrounding context. Encoder only models learning complex contextual representations by reconstructing (predicting) masked parts of the input, rather than reconstructing the entire input sequence.
Since the attention mechanism in encoder only models allow tokens to attend to previous and subsequent tokens, the attention mechanism is called bidirectional attention. Hence the context representation obtained from the bidirectional attention mechanism is called bidirectional context, which capture complex relationships and dependencies within sentences. The bidirectional context of a token captures two-sided dependencies of the token in a sentence.
Decoder Only
Decoder only transformers are models consist of decoder stacks. Decoder only models are well suited for generative NLP tasks because these models are designed to take a prompt and predict the next token in the prompt. GPT is an example of a decoder only model.
During pretraining, a typical decoder processes the entire input sequence in parallel (in a single step) to generate the entire output sequence where each predicted token in the output sequence is based on the preceding tokens. Decoder only models are pretrained with a language modeling objective to predict the next token based on previous tokens. Also, decoder only models are pretrained with a constrain on the attention mechanism such that each token in the input sequence attend only to previous tokens. Hence decoder only models implement the causal attention or autoregressive attention.
During inference, decoder models perform auto-completion iteratively by predicting the most probable token given the preceding tokens. That means, the tokens in the output sequence are generated one at a time where each predicted token is conditioned on the previous predictions. At each time step, the generated token is appended to the sequence of previously generated tokens to obtain the decoder’s new input sequence. This new input sequence is then fed into the decoder to generate the next prediction. The process is repeated until the last output \(EOS\) is generated. Decoder only models are autoregressive models because they utilize previous predictions or tokens to generate a new prediction during each time step (iteration) at inference time.
Encoder Decoder
Encoder decoder transformers are models that have both the encoder and decoder components. Encoder decoder models capture complex relationships between sequences of text. Encoder decoder models are suitable for sequence-to-sequence tasks such as machine translation and text summarization. Encoder decoder models in the context of NLP are also called sequence-to-sequence (seq2seq) models because these models take input sequences and generate output sequences. The encoder encodes the input sequence into a rich vector representation. The decoder predicts the most probable token conditioned on the output of the encoder and the decoder’s input (target sequence).Examples of encoder decoder models include BART and T5 models.
BERT
BERT stands for Bidirectional Encoder Representations from Transformers and was introduced in 2018 by Jacob Devline and his colleagues at Google in the paper, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. BERT is an encoder only transformer with a pretraining goal of learning embeddings that capture rich, complex, and bidirectional contextual information for tokens within each input sequence and relationships between pairs of sentences in the corpus.
Pre-trained BERT models for generating BERT embeddings can then be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks. BERT embeddings can be further processed downstream for a wide variety of NLP tasks including text classification, named entity recognition, text similarity, question answering, text generation (when BERT embeddings are used to provide context to decoders), etc.
BERT’s pretraining objectives include Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). The pretraining objective of BERT’s MLM task is build a model that predict missing (masked) tokens in an input sequence using surrounding (bidirectional) context.
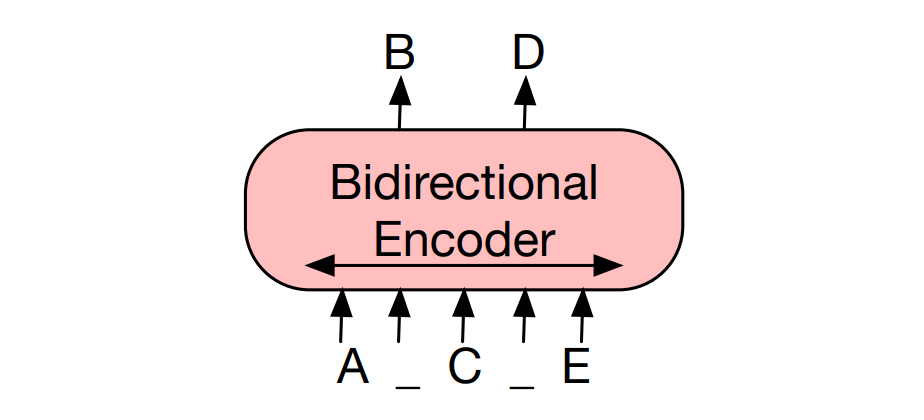
During BERT’s MLM task, a proportion (15%) of tokens in the input sequence are randomly masked. For example, some tokens in the the input sequence God loves everybody in the world could be masked to obtain God [MASK] everybody in [MASK] world. Note that since masked tokens don’t exist during fine-tuning, there is a mismatch between pretraining and fine-tuning. To mitigate this, when 15% of tokens are randomly selected to be predicted, 80% of the selected tokens are masked with [MASK], 10% is replaced with random tokens to introduce noise, and 10% are unchanged to help the model handle situations where tokens to be predicted are not masked with [MASK].
The tokens (masked and unmasked) in the input sequence are processed in parallel through the encoder layers. The output embeddings of the encoder stack represent bidirectional contextual information for the tokens in the input sequence. A linear layer is used to project the context embedding for each token into logits. The logits for each token position are then converted by the softmax output layer into a probability distribution over the entire vocabulary for each token position.
During backpropagation, the probability distributions for the masked tokens are used to obtain the probabilities of the true tokens that were masked. The probabilities of the true masked tokens are then used to compute the losses of the true masked tokens. The total loss is computed by summing all the losses for the true masked tokens. The gradients of the total loss with respect to the model parameters are computed and used to update the model parameters through the gradient descent optimization rule.
NSP (Next Sentence Prediction) is another training objective implemented alongside MLM for each input sequence. NSP is designed to help BERT understand relationships between pairs of sentences. The NSP objective during BERT’s pretraining is achieved by predicting that the next sentence follows the current sentence. Hence the pretraining sample for the NSP task consists of a sentence and the next sentence packed together and labelled.
Creating pretraining pairs for the NSP task involves generating a mix of both positive and negative examples. That is, 50% of the time, the current sentence is followed by the actual next sentence and labelled IsNext. Similarly, 50% of the time, the current sentence is followed by a random next sentence from the corpus and labelled NotNext.
NSP is a binary classification task where the output layer computes the probability of the label IsNext given the input sequence. The pretraining objective is to maximize the probability of correctly labeling relationship between the two sentences.
For an MLM task, the input sequence for the BERT model is one sentence. For an NSP task, the input sequence consists of two sentences packed together in the format, [CLS] Segment A [SEP] Segment B [SEP]
where:
[CLS]= start of a new sentence[SEP]= separation between sentences or the end of a sentence.
The tokens in the input sequence for the NSP task are converted to token embeddings, which capture the meaning of tokens. These embeddings are further enriched with positional embeddings, which capture the positions of tokens in the sequence and segment embeddings which indicate the segments associated to the tokens. That is, the input embedding for each token is:
\[ \text{input embedding} = \text{token embedding} + \text{positional embedding} + \text{segment embedding} \] The encoder stack in BERT processes each input sequence to produce output embeddings that capture rich, bidirectional contextual information for each token in the sequence. The output embedding of the [CLS] token is used to capture information from the entire sequence. This token essentially aggregates the contextual information from both sentences.
The embedding of the [CLS] token (or the pooled output for the entire sequence) is fed into a linear layer to produce a single logit value. The logit is passed through the sigmoid activation function to obtain a probability score reflecting the probability that Sentence B actually follows Sentence A. The binary cross-entropy loss is computed based on the predicted probability and the actual label (IsNext or NotNext). The gradients of the loss with respect to the model parameters are then used to update the model parameters, and this process is repeated for each training sample.
The main goal of training a BERT model is to learn the BERT embeddings which can be used for other downstream NLP tasks. After training a BERT model, the last hidden state of the encoder stack (before the MLM or NSP output layer) contains the BERT embeddings. The encoder stack can be combined with a task-specific head such as a classification head to achieve a classification task.
Other encoder only model include BERT’s variants such as DistillBERT, RoBERTa:
- BERT was the first encoder-only transformer.
- DistilBERT is smaller, less memory intensive and faster.
- RoBERTa is trained with more data, has no Next Sentence Prediction (NSP), and has a better performance.
- XLM is a cross-lingual language model.
GPT
GPT stands for Generative Pretrained Transformer. GPT models have been spearheaded by OpenAI. The first GPT model was introduced in a paper titled “Improving Language Understanding by Generative Pre-Training” (Radford et al., 2018). GPT models are examples of decoder only models.
GPT models are autoregressive models because at inference time, the decoder predicts the next token one at a time based on the previous tokens or predictions.
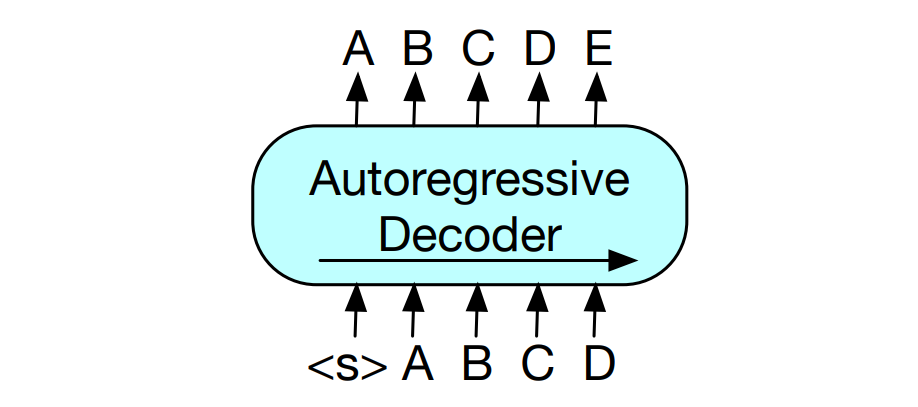
The decoder block of a GPT model consists of a masked multi-head self-attention layer, feed-forward network, and residual connections with layer normalization applied after the self-attention and feed-forward layers in the decoder block as follows:
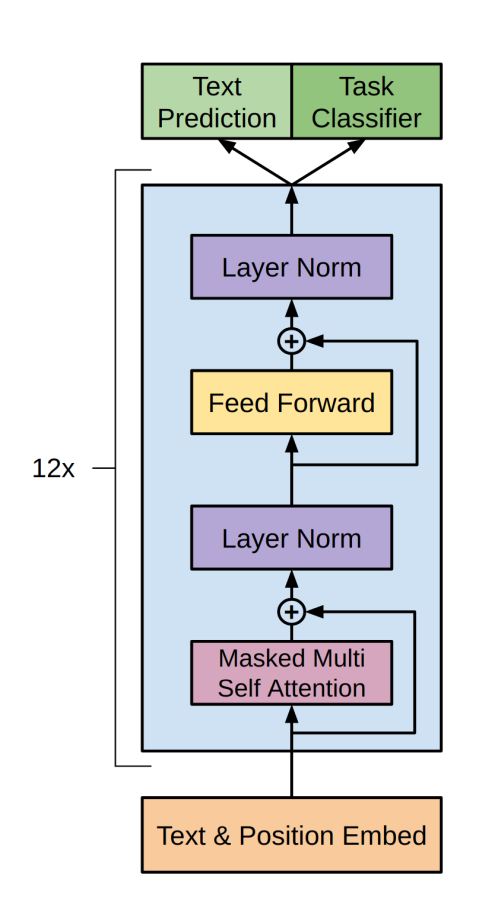
There are two phases involved in training a GPT model: the pretraining phase and fine-tuning phase. The pretraining objective of a GPT model is a language modeling objective, where the model is trained to predict the next token given the previous tokens (context).
Hence, self-supervised training is used to train a GPT model where a sliding window approach is used to create overlapping sequences of fixed length. Each sequence is a training sample consisting of input tokens and a target token. For example, a sequence such as God loves everybody consists of the input tokens or context, God loves, and the target token, everybody.
Forward pass and backpropagation are used to pretrain the model. During the forward pass, tokens within each input sequence are converted to token embeddings. The token embeddings are enriched with position embeddings to obtain the input embeddings. These embeddings are processed through multiple layers of decoder blocks, which include multi-head self-attention mechanisms and feed-forward networks, with layer normalization and residual connections.
The final output of the encoder stack is passed through the linear layer to generate logits for each token position. For each token position, the logits are processed in through the softmax output layer to produce a probability distribution over the vocabulary.
For each token position, the probability distribution contains scores representing the probability of each vocabulary token being the next token in the sequence given the preceding tokens. For each token position, the probability of the actual next token given the preceding tokens is used to compute the cross-entropy loss. The total loss for the entire sequence is the computed by summing the cross-entropy losses associated with the tokens in the sequence.
The gradients of the total loss with respect to the model parameters are computed and used to update the model parameters during backpropagation. The forward pass and backpropagation process is repeated across many training samples and epochs, allowing the model to learn from a wide variety of contexts to improve its ability to predict the next token in a sequence.
Note that the loss for each token position is computed as: \(Loss = - \log{\hat{y}_{\text{actual next token}}}\)
where \(\hat{y}_{\text{actual next token}}\) is the softmax probability of the actual next token given the context (preceding tokens).
The probability of a token \(w_i\) given the context can be calculated using the softmax function as:
\[ \hat{y_i} = P(w_i \mid \text{context}) = \frac{\exp(\text{logit}_i)}{\sum_{j} \exp(\text{logit}_j)} \]
where:
- \(\text{logit}_i\) is the logit (raw score) for the vocabulary token \(w_i\).
- \(\text{logit}_j\) is the logit for token \(w_j\), where \(j\) ranges over all tokens in the vocabulary.
- The denominator is the sum of the exponentials of the logits for all tokens.
The GPT model was pre-trained on BookCorpus to predict the next word and it achieved excellent results on downstream task such as classification.
After pretraining, a GPT model is then fine-tuned. Fine-tuning is transfer learning where the model is further trained on a specific dataset to adapt it to a particular task, need or domain. Fine-tuning is transfer learning because pretrained parameters are used to further train a model with a different dataset to achieve a specific task. So fine-tuning does not start from scratch with randomly initialized parameters but uses parameters that were already learned during pretraining. This speeds up the training process and is beneficial in situations where the training data or corpus is small. Fine-tuning also allows the model to generate more accurate responses for a specialized task.
A company might fine-tune a GPT model on its own customer service interactions and FAQs. This specialized model would then be able to handle customer inquiries more effectively by providing responses that are specific to the company’s products, services, and policies.
A healthcare organization could fine-tune a GPT model on a dataset of medical literature, patient records (anonymized), and clinical guidelines. This fine-tuned model could assist healthcare professionals by providing more accurate and contextually relevant information for diagnosing and treating medical conditions.
Variants of the GPT model have been produced such as GPT-2, capable of generating long and coherent sequences of text and completing prompts. GPT-2 was upgraded to GPT-3 having 175 million parameters and is able to generate text and also incorporate few shot learning. Few shot learning is when a few examples are provided to the model on how to accomplish a task. GPT-3 is not open sourced, hence the implementation details are not publicly available.
T5
T5 stands for Text-To-Text Transfer Transformer and was introduced in the paper titled “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer” by Google Researchers (Raffel et al. 2019). T5 is an encoder-decoder model based on the transformer architecture. T5 can be used for tasks like translation, summarization, question answering, and more.
The basic idea underlying T5 is to treat every text processing problem as a text-to-text problem, which means both the input and the output are represented as text (Raffel et al. 2019).
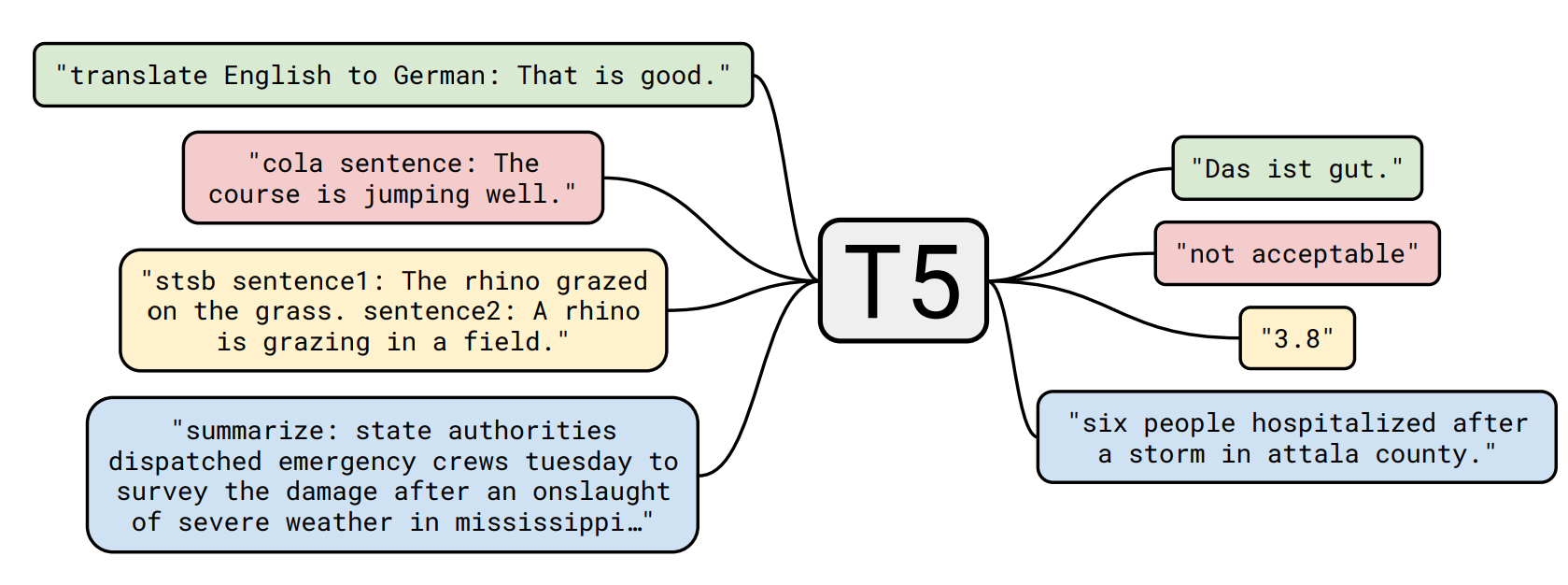
T5 is designed for transfer learning, where the model is first pretrained on a data-rich task before being fine-tuned on downstream tasks. It was found that models that were pretrained to capture language patterns and contextual information performed better when fine-tuned on specific datasets compared to if the models were only trained directly with the specific datasets.
Pretraining the model with generic data such as the C4 dataset allows the model to model learn contextual information for various tokens and fundamental language patterns such as syntax, grammar, and semantics. The patterns and relationships learned in the corpus are transferable to downstream tasks. T5 was pretrained on the C4 dataset, a cleaned version of Common Crawl’s web crawl corpus (focused on English text).
Unsupervised (self-supervised) learning is used during pretraining with a denoising objective to predict or reconstruct masked (corrupted) parts of input sequences. The unsupervised pretraining objective is to infer missing parts of text to allow the model to learn general language patterns and contextual relationships in the text, useful for downstream tasks.
During pretraining, each input sequence is corrupted by randomly dropping out tokens and replacing the span of dropped-out tokens with sentinel tokens that are unique for that training example as shown below.

The output sequence (target) then consists of the dropped-out spans, delimited by the sentinel tokens used to replace them in the input plus a final sentinel token. Hence the training samples consist of text data formatted as text-to-text pairs.
Each corrupted input sequence is fed into the encoder component (BERT style) of the model and processed through multiple layers of the encoder stack to produce a rich, bidirectional contextual representations of the input text. These encoder output embeddings are then passed to the decoder (encoder-decoder self attention layer) for further processing.
The target sequence (shifted to the right by one position) and the encoder’s context representation are processed through the decoder stack to produce the final ouput of the decoder stack. This final output is passed through the linear layer to produce logits for each token position, and these logits are further processed through the softmax layer to generate the probability distributions over the vocabulary for the token positions.
For each token position in the target sequence, a cross-entropy loss is calculated based on the probability score of the actual tokens in the target sequence. The total loss is obtained and the gradients of the total loss with respect to the model parameters are computed and used to update the model parameters.
The pretraining objective is to maximize the probability of the actual tokens in the target sequence, hence the cross entropy loss is based on the probabilities of the actual tokens. Since the T5 pretraining objective is to reconstruct the masked input sequence tokens, only the loss for the the target sequence tokens (masked input sequence tokens) are used for backpropagation to update the model parameters.
The pretrained T5 model was fine-tuned on various datasets for different tasks as follows:
- GLUE: a collection of datasets for evaluating general language understanding across tasks such as sentiment analysis, similarity between sentence pairs, etc.
- CNNDM (CNN/Daily Mail): used for abstractive text summarization.
- SQuAD: used for machine reading comprehension and question answering.
- SuperGLUE: a collection of datasets for more challenging language understanding tasks compared to GLUE.
- EnDe, EnFr, EnR: parallel corpus used for machine translation, translating text from English and another language (German, French, Romanian respectively)
Generally, the model is pretrained on unsupervised tasked and fine-tuned on specific supervised tasked. Fine-tuning can be implemented such that \(N\) pretrained models are further separately trained for \(N\) specific tasks. Alternatively, multi-task fine-tuning can also be implemented where a model is simultaneously trained on multiple tasks. A single model architecture is used for various tasks and data formatted as text-to-text.
Multi-task fine-tuning has the following benefits:
- Shared features and representations across tasks help improve performance (compute time).
- Multi-task fine-tuning allows the model to learn from a diverse set of data and tasks which can help the model generalize more effectively.
- Knowledge gained from one task can be transferred and utilized in other related tasks.
T5 is a unified framework because the same model architecture is used to learn from multiple tasks. Note that during fine-tuning, prefixes corresponding to each task are prepended to the input sequence to clearly specify the task the model should perform, leveraging a unified framework to handle multiple tasks efficiently.
For example, a prefix can be added to an input sequence for a translation task as follows:
- Input: “translate English to French: the weather is sunny today.”
- Output: “le temps est ensoleillé aujourd’hui.”
At inference time, T5 processes input text through its encoder to obtain contextualized representations. The decoder then generates text based on these representations, using autoregressive decoding to produce coherent and contextually appropriate output.
BART
BART stands for Bidirectional and Auto-Regressive Transformer and was introduced in 2019 by Facebook AI Research (FAIR) in the paper “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension”. BART is a transformer model with a bidirectional encoder similar to BERT and an autoregressive decoder similar to GPT.
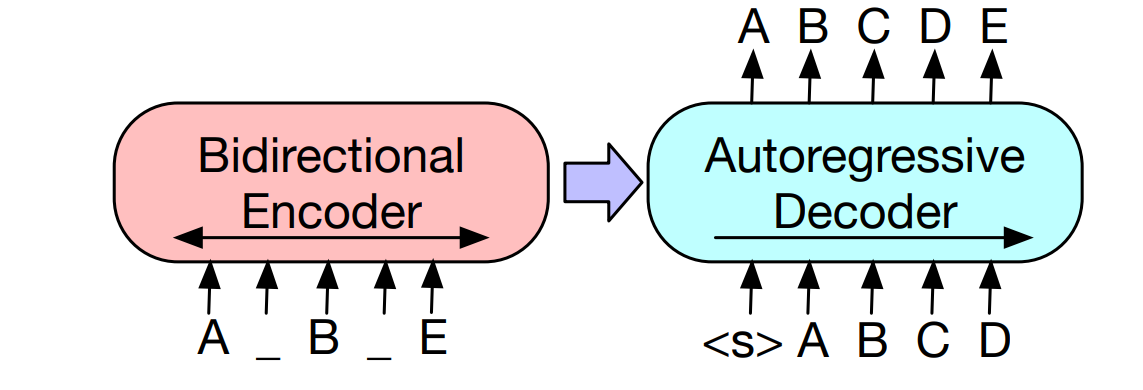
BART combines the pretraining concept of BERT and GPT within the encoder decoder architecture with a denoising autoencoder pretraining objective to reconstruct corrupted input text.
The input sequence is corrupted through various corruption methods including:
- token masking: Randomly replacing some tokens in the input text with a special [MASK] token.
- token deletion: Randomly removing some tokens from the input text.
- sentence permutation: Shuffling the order of tokens in the input text.
- text infilling: randomly sample a text span and replace each span with a single [MASK] token.
During pretraining,the bidirectional encoder converts the corrupted text into a context embeddings and passes these embeddings to the autoregressive decoder. The autoregressive decoder processes the decoder’s input (the target sequence obtained by shifting the original text one position to the right) and the encoder’s output to compute the probability distribution (over the vocabulary) for each token position in target sequence.
For each token position in the target sequence, the cross-entropy loss is computed using the probability of the actual next token given the previous tokens in the target sequence. The cross entropy loss for each target sequence is computed as the total loss (sum of losses for all token positions in the target sequence).
Backpropagation is implemented by computing the gradients of the total loss with respect to model parameters and using the gradients to update the model parameters. BART is pre-trained by corrupting text with various noising functions and letting the model to reconstruct the original text from the corrupted input.
BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. BART is can handle a range of NLP tasks effectively, including text generation, summarization, translation, and question answering.
- BART is pretrained using a large corpus with various noise types to learn robust representations of text.
- After pretraining, BART can be fine-tuned on specific tasks using task-specific datasets. This fine-tuning helps adapt the model’s general knowledge to perform well on specific tasks.
For sequence classification tasks, the same input is fed into the encoder and decoder, and the final output of the decoder stack is fed into new multi-class classifier head.
BART has an autoregressive decoder, hence BART can be fine-tuned for sequence generation tasks such as abstractive question answering and summarization without any architectural changes.
BART can also be fine-tuned for a machine translation task: BART’s encoder embedding layer is randomly initialized with new values. The entire model is then trained end-to-end, by feeding the encoder with the input sequence (in the source language) and the decoder with the target sequence (in the target language).