Lesson 20: Attention

Attention
Attention mechanisms are considered an enhancement over traditional encoder-decoder architectures in sequence-to-sequence models. An encoder decoder model uses an encoder network to transform an input sequence into a hidden context representation, which is then used to initialize a decoder network that generates the output sequence of text.
In an encoder decoder model with RNNs, the requirement to transform input into to a hidden context representation (bottleneck) forces all information in the input sequence to be compressed into the bottleneck representation. This bottleneck representation may struggle to capture long-range dependencies or information at the beginning of the input sentence effectively, especially in longer sequences.
Additionally, there is no parallelization with RNN architectures because the sequential data is processed time step by time step. This can result to slow performance for long input sequences.
Hence, two major problems with the encoder decoder model with RNNs is that, the last hidden state of the encoder representing the entire input sequence does not effectively capture information from earlier parts of the sequence and sequential processing is slow for long sequences.
These problems of capturing long-term dependencies and processing input tokens sequentially can be solved using different approaches such as:
- standard feed forward neural network architecture,
- RNN-based encoder decoder with attention, and
- a transformer with self-attention.
Feed Forward Neural Network with Sequential Data
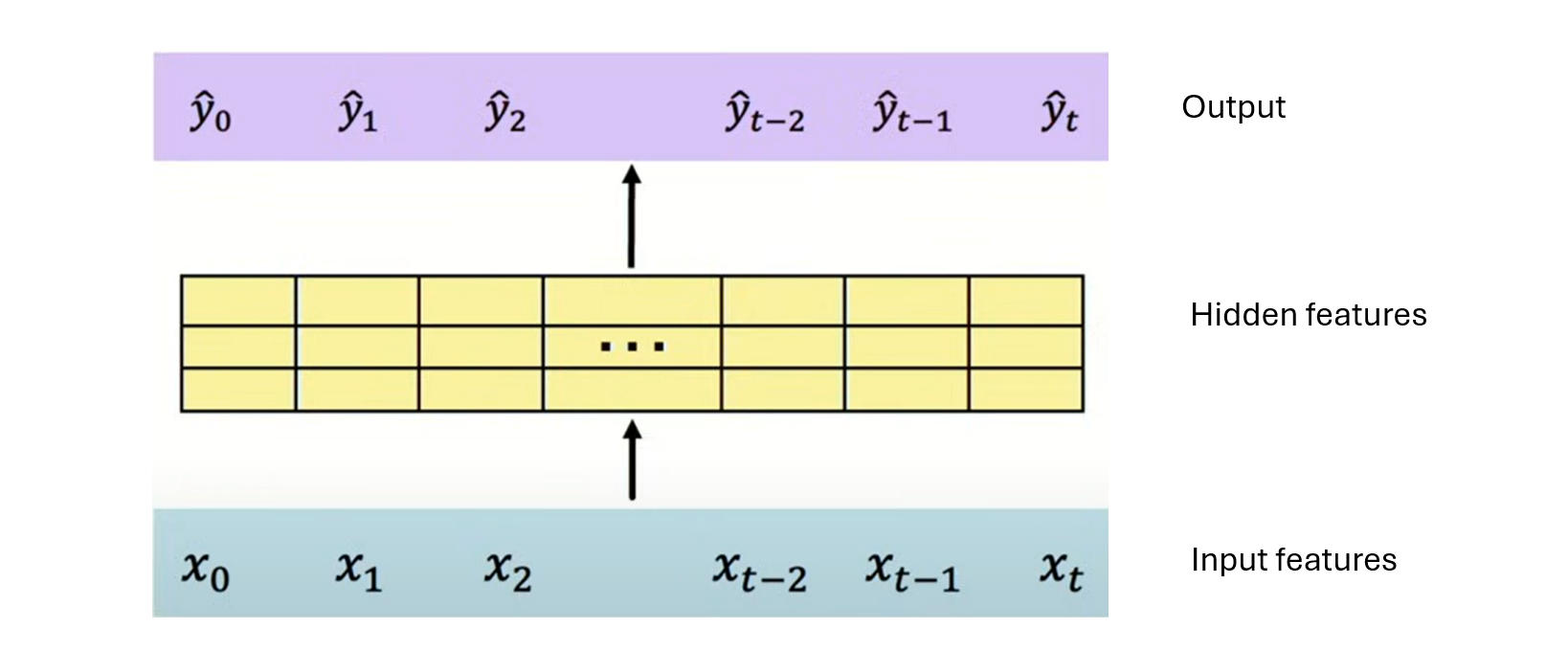
A traditional feed forward neural network can be used to process sequential data to address the issue of loosing information and no parallelization with RNNs. This approach is a naive approach. Let’s assume that the modeling task is to predict the next word in a sequence. The tokens in the sequence are first represented as embeddings, then concatenated into a single vector. The input vector is fed into the deep neural network and transformed into hidden features, which are further transformed into a probability distribution over vocabulary words.
At inference time for text generation, an initial sequence of tokens (prompt) is fed into the feed forward neural network model to generate the the probability distribution over vocabulary words.The predicted next word is selected using greedy sampling or temperature sampling.
Greedy sampling is when the word with the highest probability is then selected as the predicted word. Hence greedy sampling is argmax sampling. Temperature sampling is a stochastic sampling where a scalar temperature parameter used to control the diversity and randomness of the predicted word. The softmax function with temperature \(T\) is defined as: \(\text{softmax}(z_i) = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}}\). When \(T >1\) smooths out the distribution, making all probabilities more equal resulting to diverse choices and varied outputs. When \(T\) gets closer to 0, the softmax distribution becomes more deterministic and produces similar results as greedy sampling. The probability distribution is then used to sample the next token. Hence temperature sampling is stochastic sampling.
The predicted word is then used to update the input sequence by appending the sampled token to the current context window and sliding the window forward to include the new token. The prediction process is repeated iteratively to generate subsequent tokens until an end token or a maximum length is reached.
Though a feed forward neural network allows us to process the tokens in an input sequence in parallel, this architecture does not scale well as increase in context window size decreases computational efficiency. Additionally, this a feed forward neural network does not capture the order of words and do not have a long memory (only words in the context window influence predictions because the model does not maintain memory of tokens that are outside the immediate context window).
The Attention Mechanism
In traditional encoder-decoder models with RNNs, the entire input sequence is summarized into a context vector. This context vector is a bottleneck representation, potentially losing important information from the input sequence.
The attention mechanism allows input to be processed in parallel, hence improving computational efficiency. Parallel processing of tokens in a sequence makes neural network architectures with attention mechanism more efficient in handling long sequences.
The attention mechanism solves the problem of losing important information in input sequences by allowing the decoder network in the encoder decoder model to capture information from all tokens in the input sequence while paying more attention to tokens in the input sequence that are more relevant for the prediction.
The attention mechanism allows the decoder network of an encode decoder model to use the entire input sequence at every decoding step while selectively attending to important tokens through the assignment of weights.
An Encoder Decoder Model with Attention
Compared to a traditional encoder decoder model with RNNs, an encoder decoder model with the attention mechanism generate a dynamic context vector for each decoding step. Each context vector is computed as the weighted sum of the encoder hidden states, where the weights are determined by the attention weights.This dynamic context vector captures the important information from the input sequence relevant to the current decoding time step.
The architecture for an encoder decoder model with attention is as shown below.
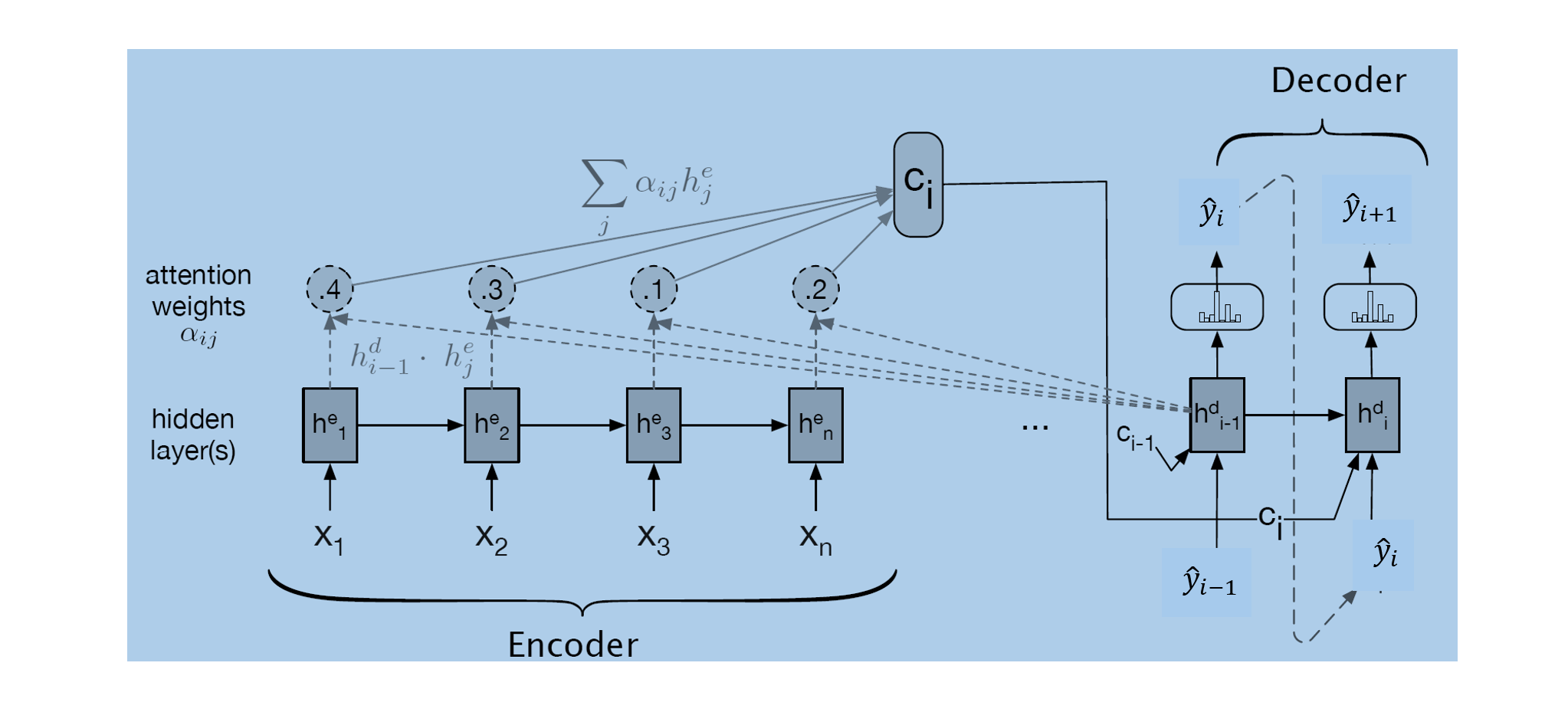
The encoder network transforms the input sequence into hidden vectors, \(h^e_1, h^e_2, h^e_3, ..., h^e_n\).
The context vector \(c_i\) used at \(ith\) decoder step is the weighted sum of the encoder’s hidden vectors. This context vector represents the relevance information from the original input text needed for the \(ith\) decoder step.
\[ c_i = \sum^n_{j=1} {\alpha_{ij}h^e_j} \] where:
\(\alpha_{ij} =\) is the attention score or attention weight indicating the relevance of the encoder’s hidden state \(h^e_j\) to the current or \(ith\) decoder step, captured in \(h^d_{i-1}\). \(\alpha_{ij}\) is a normalized similarity score where the similarity score could be computed using a dot product.
\[ score(h^d_{i-1}, h^e_j) = h^d_{i-1} \cdot h^e_j \] Note that this score is computed for each hidden vector in the encoder network.
The attention weight is a softmax normalized similarity scores:
\[\begin{align} \alpha_{ij} &= sofmax(score(h^d_{i-1}, h^e_j)) \\ &= \frac{\exp(\text{score}(h^d_{i-1}, h^e_j) )}{\sum_j \exp(\text{score}(h^d_{i-1}, h^e_j) )} \end{align}\]
The current hidden state of the decoder \(h^d_i\) is computed using the previous hidden state of the decoder \(h^d_{i-1}\), the embedding of the generated word at the previous step \(\hat{y}_{i-1}\), and the context vector \(c_i\) containing relevant information from the original input sequence needed to predict the output for the current decoder step.
The current hidden state of the decoder is computed using a formula of the form:
\[ h^d_i = g(h^d_{i-1}, \hat{y}_{i-1}, c_i) \]
Note that transformers can also be used to solve the limitations of the RNN-based architecture - the inability to capture long term dependencies and lack of parallel processing of sequence tokens.Transformers, leverage self-attention to achieve robust parallel processing across sequence tokens, leading improved computational efficiency.