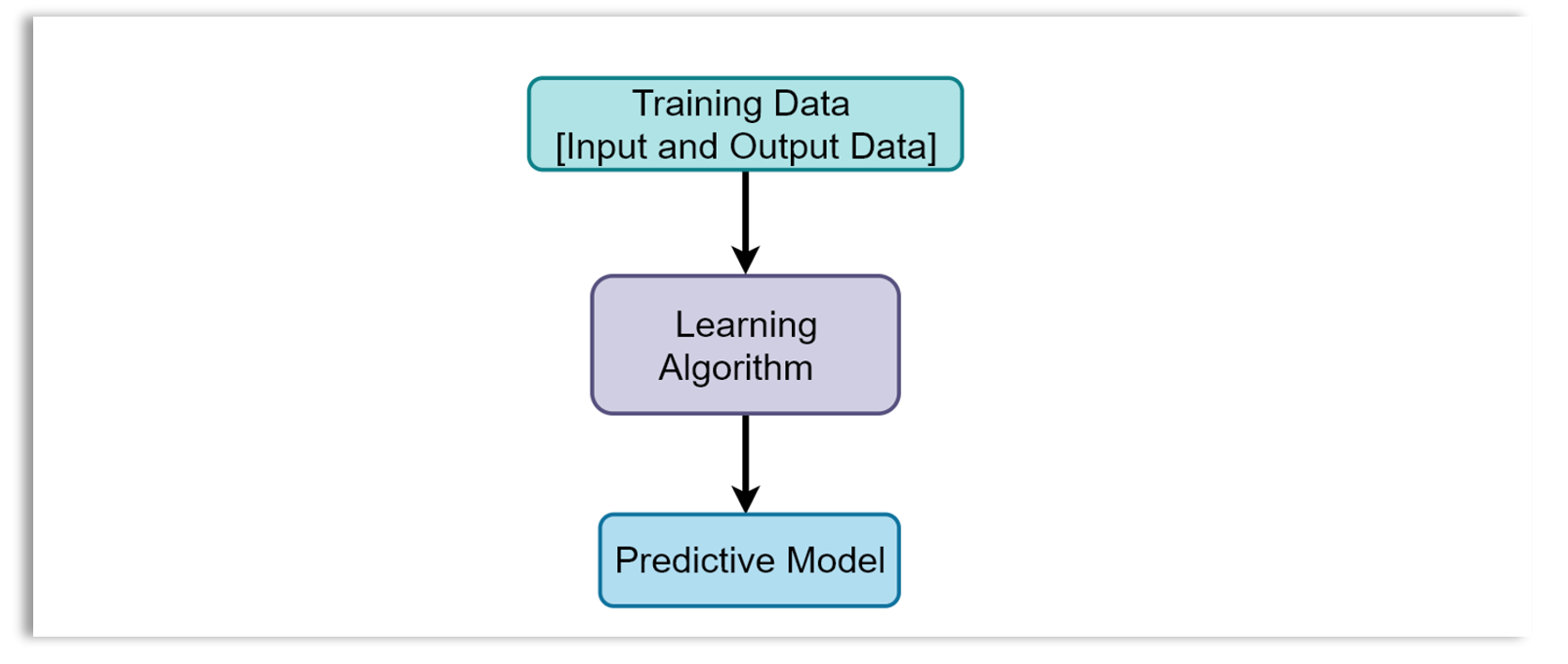
Lesson 4: Model Building and Evaluation

Model Building
A model is a representation of the reality. A model captures the relationships or patterns in your data. Some models are probabilistic, statistical or mathematical in nature while others are not. Mathematical models are functions that approximate the relationships in the data. What is the goal of model building?

The goal of modeling (or model building) in data science or machine learning is to learn (or train) the model that represents the relationships in the data well. An algorithm and data are needed to build a model. The algorithm is fed with the data to learn the model. After training a model, the model is then used to accomplish a specific task (machine learning task).
Learning Tasks
There are different types of machine learning tasks or problems. Some common machine learning tasks are as follows:
Supervised learning
Supervised learning is a type of machine learning where the input data used to train the model is labeled. That means, the training dataset has both the input data and the corresponding output data. The task of a supervised learning algorithm is to train a model with this labeled data to predict the labels or output of unlabeled data. Supervised learning tasks can be further divided into classification and regression.
Classification: The goal of a classification task is to predict a class, categorical outcome, or label. For example, if you train a model to classify a credit card transaction as fraudulent or not fraudulent, the task you are solving is a supervised learning classification task, and the model trained for this kind of task is called a classification model. The features used for this task could include the transaction amount, merchant category, transaction location, time of the transaction, and the user’s previous transaction history.
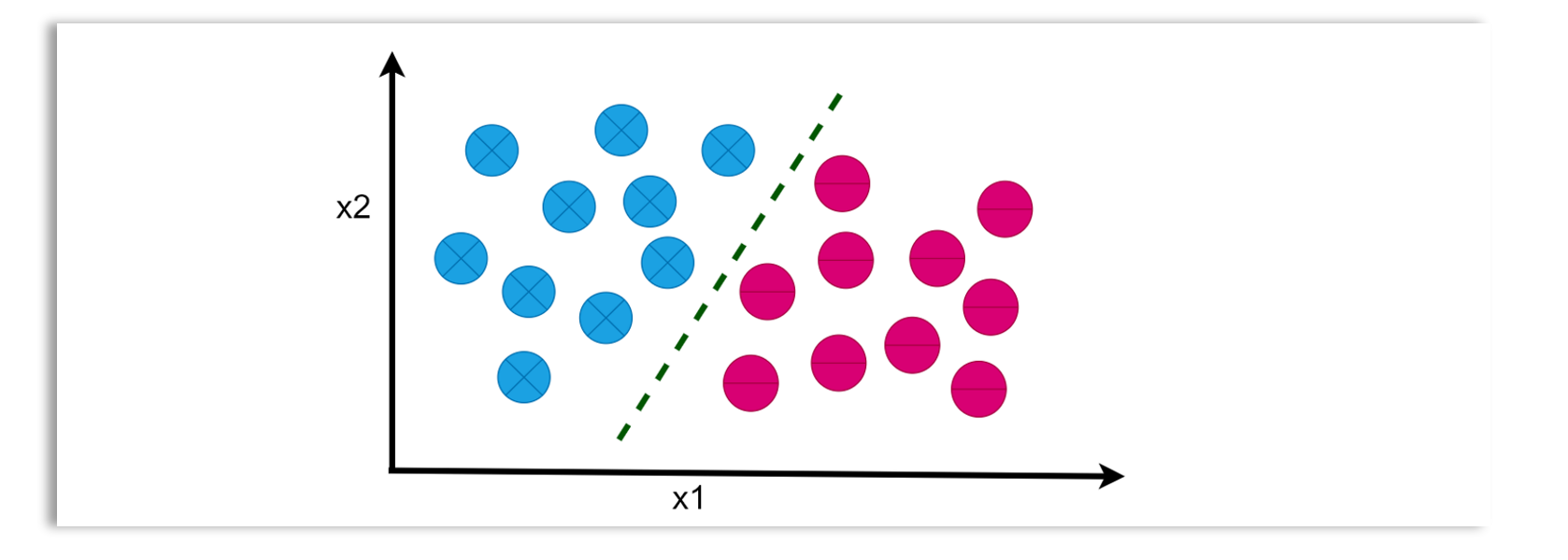 Examples of classification models include logistic regression, support vector machines (SVM), decision trees, random forests, k-nearest neighbors (k-NN), naive Bayes, neural networks, gradient boosting machines (e.g., XGBoost, LightGBM), AdaBoost, and deep learning models like convolutional neural networks (CNNs) for image classification.
Examples of classification models include logistic regression, support vector machines (SVM), decision trees, random forests, k-nearest neighbors (k-NN), naive Bayes, neural networks, gradient boosting machines (e.g., XGBoost, LightGBM), AdaBoost, and deep learning models like convolutional neural networks (CNNs) for image classification.
Regression: The goal of a regression task is to predict a continuous outcome or value. For example, if you train a model to predict the price of a house based on its features (like size, location, etc.), the task you are solving is a supervised learning regression task, and the model trained for this kind of task is called a regression model.
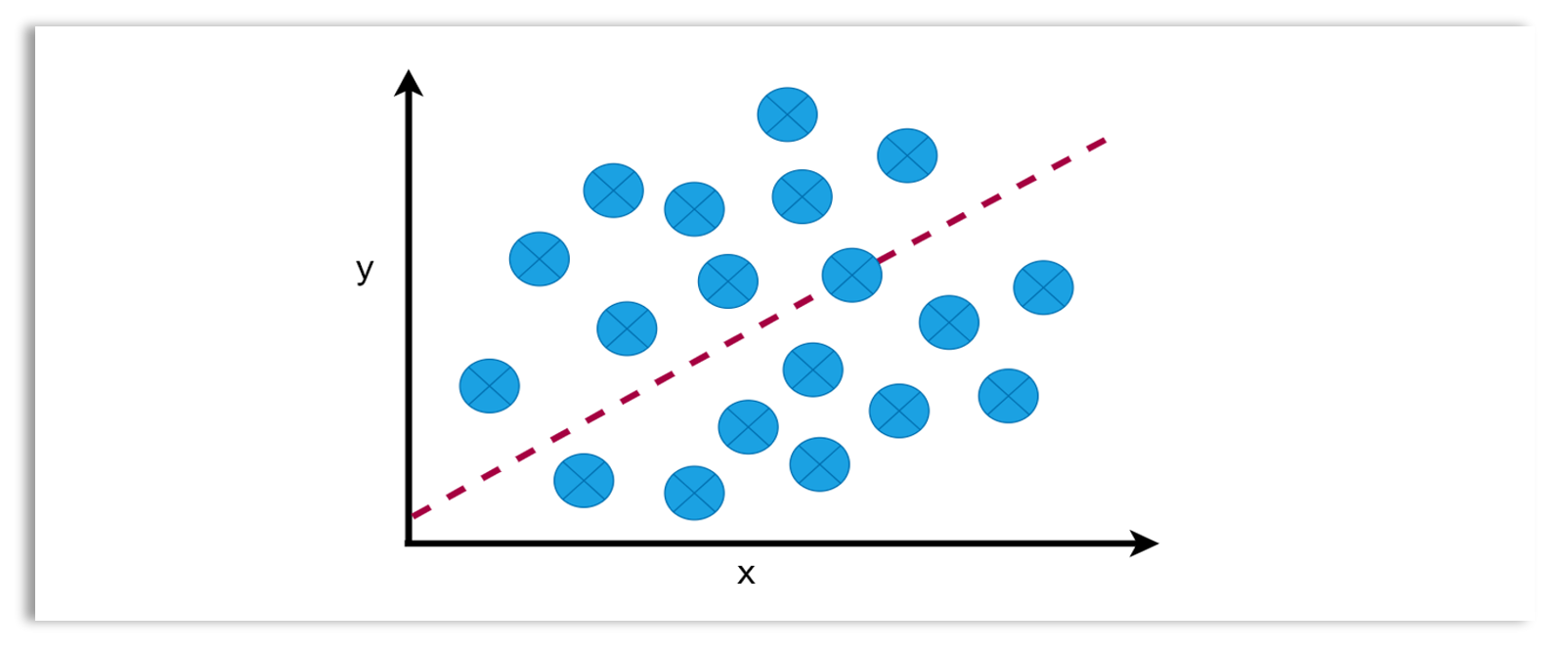 Examples of regression models include linear regression, ridge regression, lasso regression, support vector regression (SVR), decision trees, random forests, k-nearest neighbors (k-NN), gradient boosting machines (e.g., XGBoost, LightGBM), and neural networks.
Examples of regression models include linear regression, ridge regression, lasso regression, support vector regression (SVR), decision trees, random forests, k-nearest neighbors (k-NN), gradient boosting machines (e.g., XGBoost, LightGBM), and neural networks.
Unsupervised learning
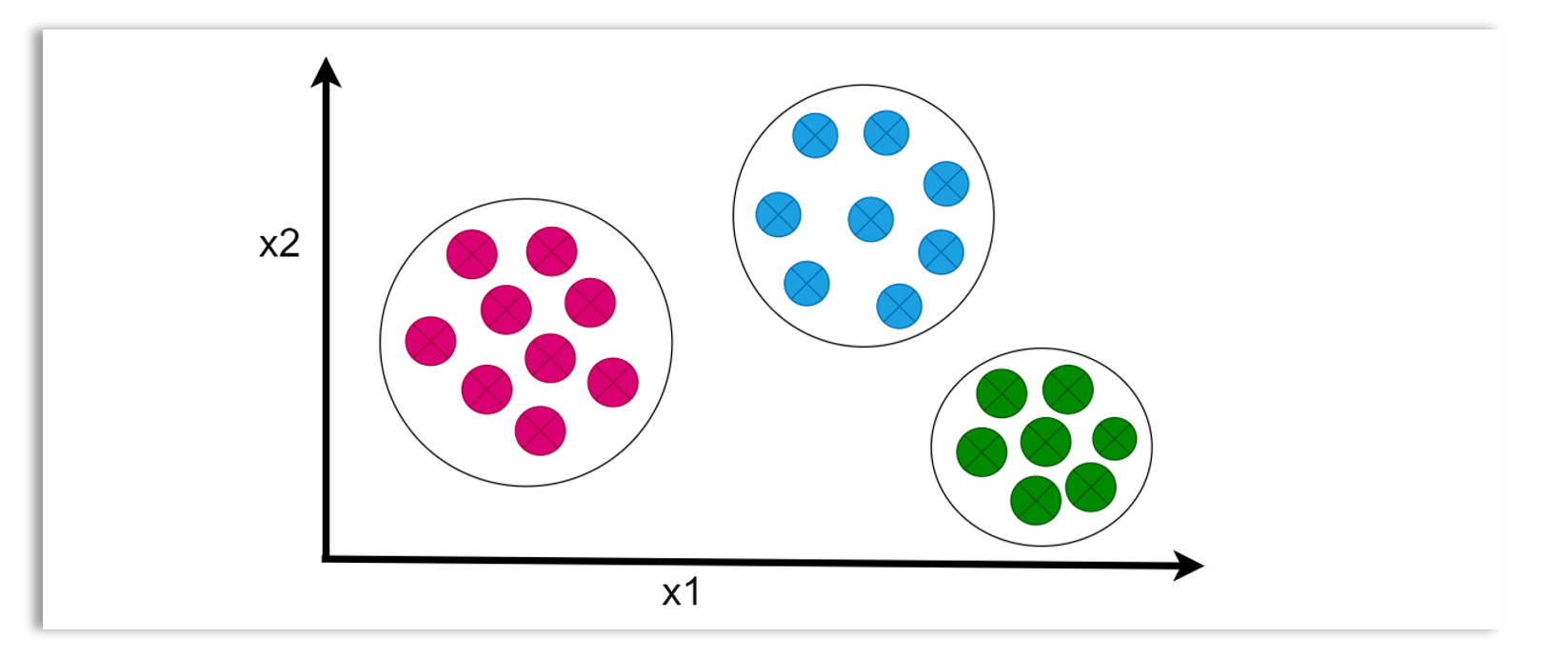
Unsupervised learning is a type of machine learning where the input data used to train the model is unlabeled. That means, the training dataset only contains the input data and lacks corresponding output data. The task of an unsupervised learning algorithm is to discover underlying patterns, structures, or relationships within the unlabeled data. Common unsupervised learning tasks include clustering and anomaly detection.
Self-supervised
Self-supervised learning is a machine learning technique where the model learns by creating its own labels from unlabeled data. This technique is commonly used in training models like GPT models, where the model is trained to predict the next word in a sequence given the preceding words as input.
Reinforcement
Reinforcement learning (RL) is a type of machine learning in which an agent learns to make decisions by interacting with an environment. The agent learns through a system of rewards and penalties: it takes actions and observes the consequences. Actions leading to desirable outcomes (rewards) are reinforced, while those leading to undesirable outcomes (penalties) are discouraged. The primary goal is to find an optimal policy that maximizes cumulative reward over time.
Model Evaluation
Model evaluation involves assessing the performance of a machine learning model for various purposes. Typically, model evaluation allows us to understand if a model generalizes well to unseen data. The performance of a model can be evaluated for several key purposes:
Assessing the model’s ability to generalize to unseen data: In a supervised learning task, when you use training data to train the model, you need to evaluate the model on test or unseen dataset to understand how well the model performs or generalize to unseen data. Note that the test set is also called the evaluation set and is not used during training. The trained model is used to predict the output given the test input data. The predictions are then compared with the actual output of the test data to measure the performance of the model.
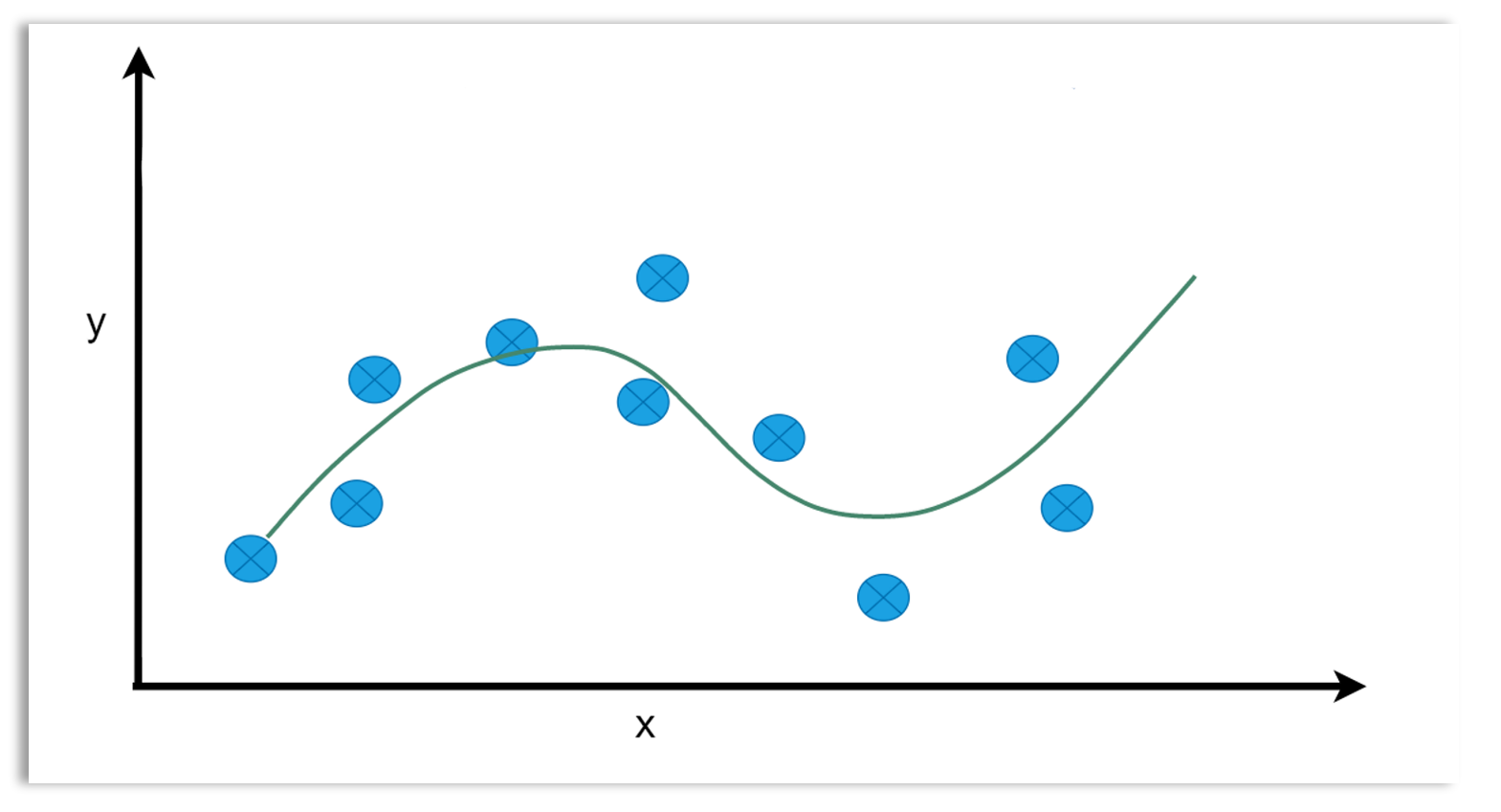
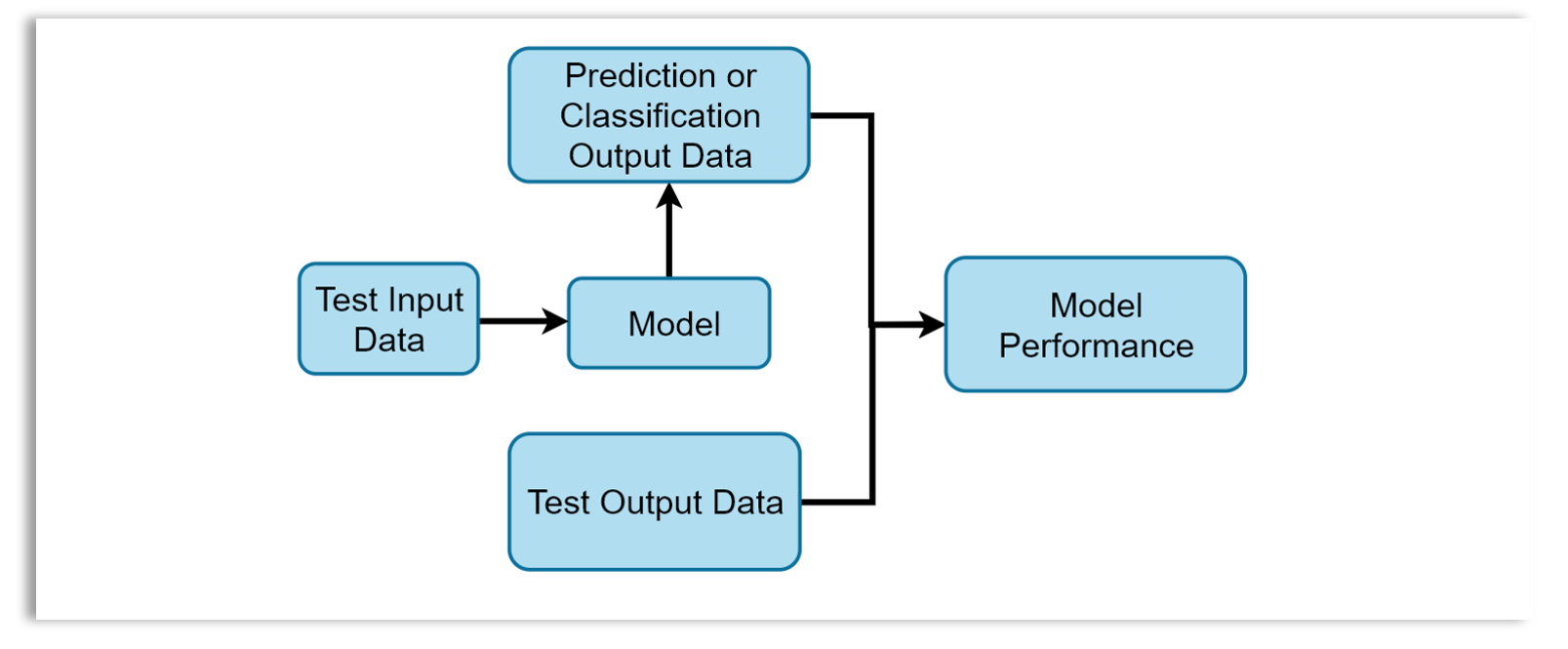 Checking for overfitting: Evaluating the model’s performance on both the training and test sets helps detect overfitting. Overfitting occurs when a model learns not only the underlying patterns but also the noise in the training data, causing it to perform poorly on new, unseen data. Overfitting occurs when the model performs well on the training data but poorly on the test data. A model that is very complex could easily overfit the data. A model that is too simple could underfit the data. Underfitting is when the model’s performance is poor both on the training and test sets. The diagrams below illustrate overfitting, optimal fit and underfitting.
Checking for overfitting: Evaluating the model’s performance on both the training and test sets helps detect overfitting. Overfitting occurs when a model learns not only the underlying patterns but also the noise in the training data, causing it to perform poorly on new, unseen data. Overfitting occurs when the model performs well on the training data but poorly on the test data. A model that is very complex could easily overfit the data. A model that is too simple could underfit the data. Underfitting is when the model’s performance is poor both on the training and test sets. The diagrams below illustrate overfitting, optimal fit and underfitting.
Overfitting 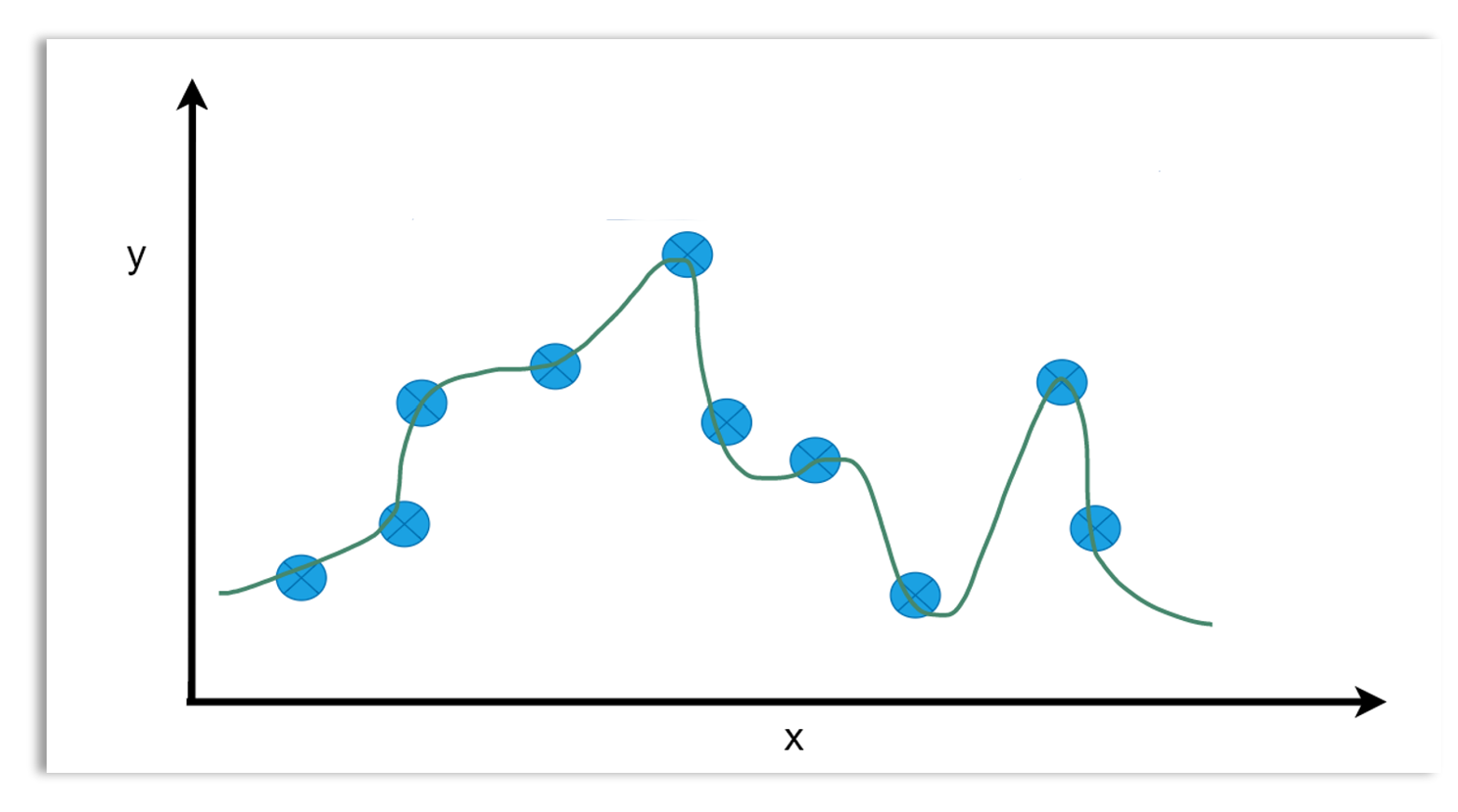 Optimal fit
Optimal fit
 Underfitting
Underfitting 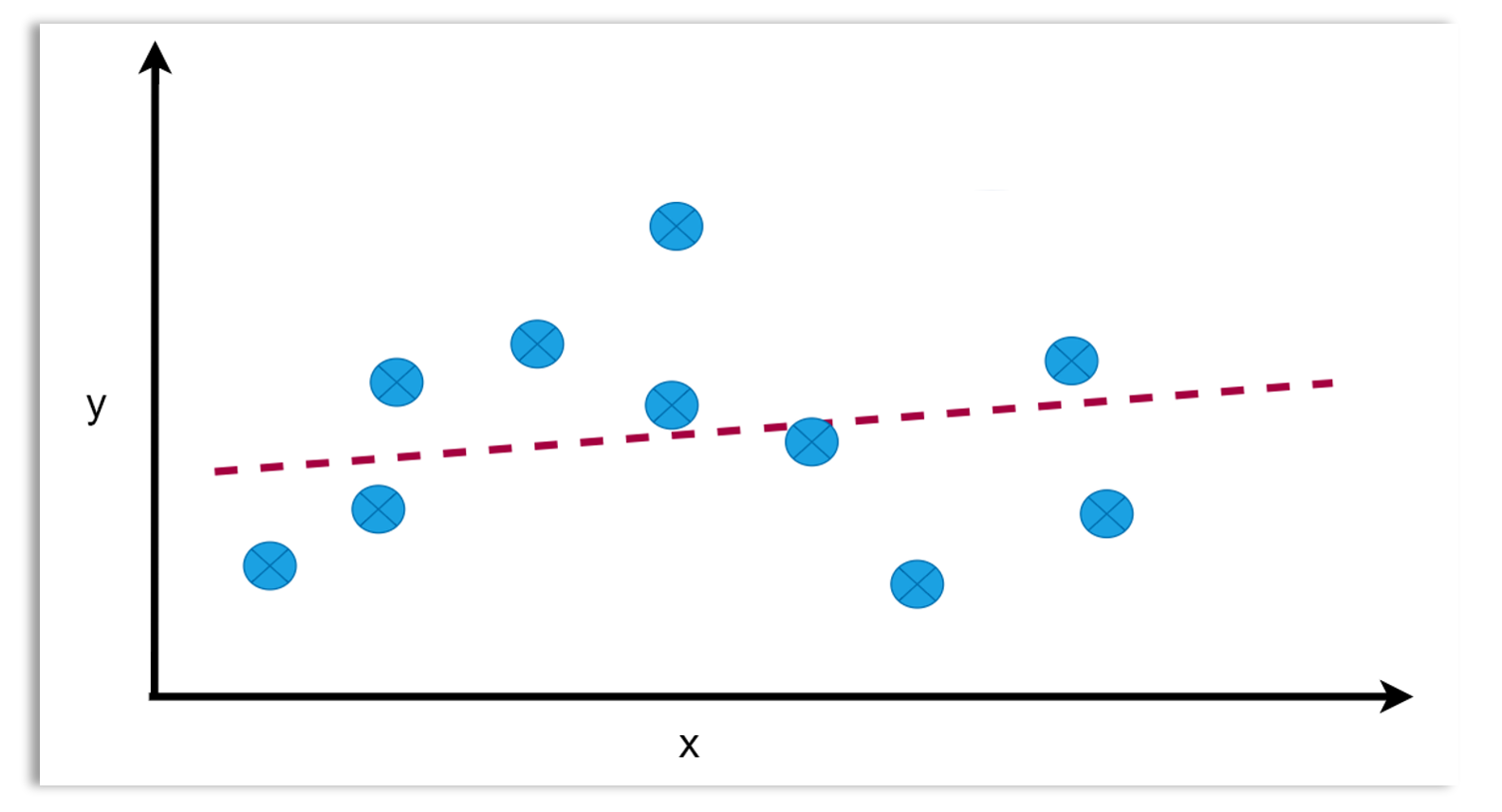
Cross validation: A model’s performance is also evaluated through cross-validation, where the dataset is divided into several folds, and each fold serves as a test set during each training iteration. Model performance is measured for each test set and averaged to obtain the final model performance. This approach is beneficial in that the model is trained and tested on different subsets of the data, simulating possible samples that can be encountered in production, allowing the model to generalize well to unseen data.
Model selection: During hyperparameter tuning or optimization, the performance of a model is evaluated on the validation set to select the model with optimal hyperparameters. In model selection, there is a single algorithm with different configurations. Model selection aims to find the hyperparameter settings or model configurations that result in the best model performance. The model whose configurations produce the best performance is called the optimal model. The optimal value of the model complexity is shown on the variance-bias trade off graph below.
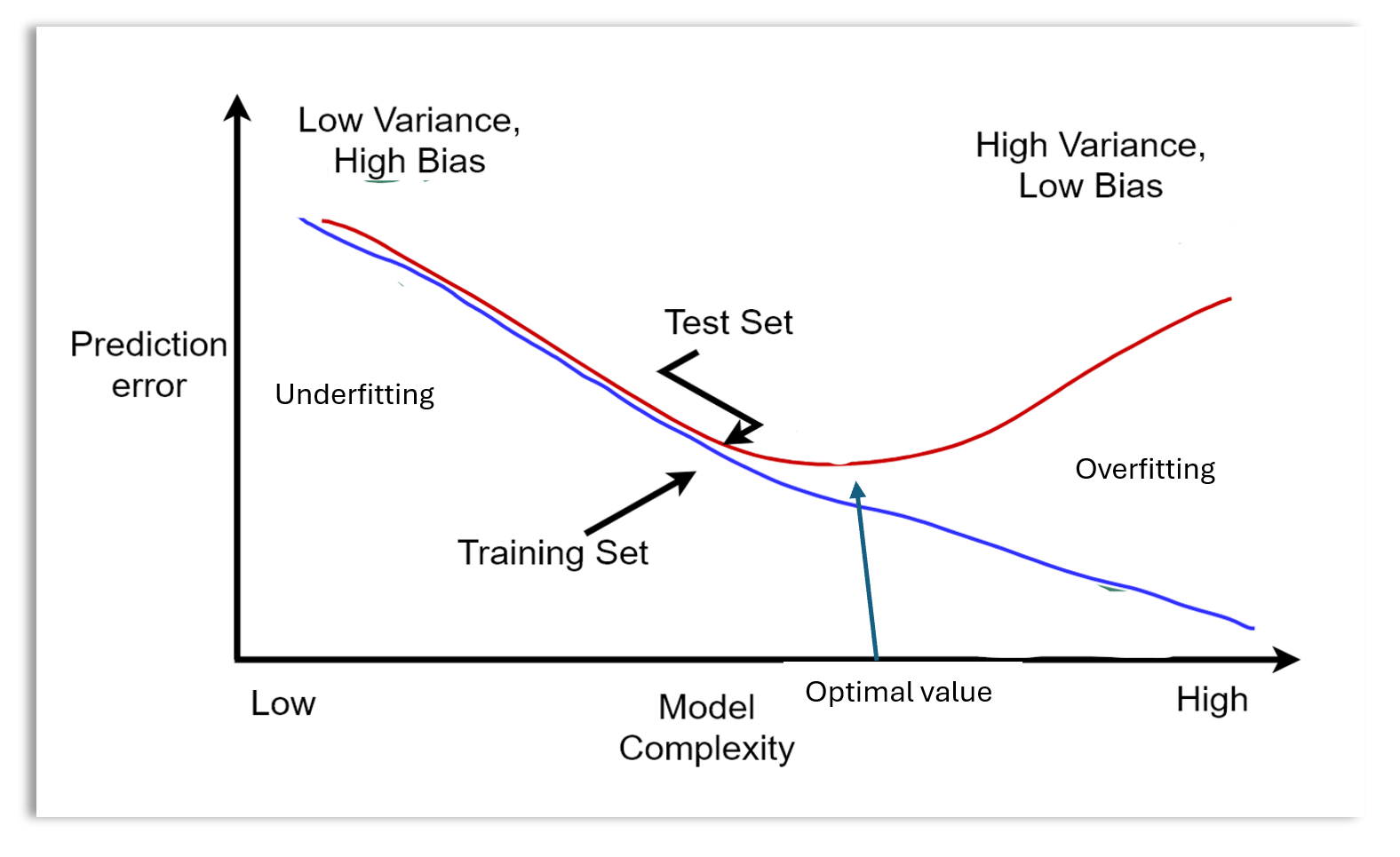
Model comparison: This involves comparing several models that have different architectures or algorithms (e.g., comparing a logistic regression model with a random forest model) and selecting the one with the best performance based on the evaluation metrics.
Model Evaluation Metrics
There are different metrics used for model evaluation. Depending on the situation, some metrics may be more suitable than others.
Metrics for regression models
- Mean Absolute Error (MAE)
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- R-squared (R²)
- Adjusted R-squared
Metrics for classification models
- Accuracy: Proportion of correctly classified instances among all instances.
- Precision: Proportion of true positive predictions out of all positive predictions made.
- Recall (Sensitivity): Proportion of true positive predictions out of all actual positive instances.
- F1 Score: Harmonic mean of precision and recall, balancing both metrics. Useful when training data is imbalanced.
- AUC-ROC: Area under the Receiver Operating Characteristic curve, representing the model’s ability to distinguish between classes.
Metrics for clustering models
- Silhouette Score: Measures how similar an object is to its own cluster compared to other clusters.
- Inertia (Within-cluster variance): Measures the compactness of the clusters, with lower values indicating better clustering.
Summary
Model building is a key phase in machine learning lifecycle, where algorithms are used to develop models that capture patterns and relationships within data. These models represent real-world phenomena and can be mathematical, statistical, or probabilistic in nature. The objective is to train a model that performs wells in solving tasks such as classification, regression, clustering, anomaly detection, etc.
Machine learning tasks can be categorized into supervised, unsupervised, self-supervised, and reinforcement learning. Supervised learning, such as classification and regression, uses labeled data to build a model that predict outcomes. Unsupervised learning task such as clustering uncovers hidden patterns in unlabeled data. Self-supervised learning generates labels from the data itself to create a training dataset as in models like GPT. Reinforcement learning enables agents to learn through rewards and penalties based on their interactions with the environment.
Model evaluation ensures the model performs well and generalizes to unseen data. Model performance can be evaluated for different purposes including, assessing generalization, checking for overfitting or underfitting, and tuning hyperparameters for optimal performance. Additionally, model comparison allows for selecting the best algorithm based on performance metrics. A thorough evaluation ensuring that models are robust and capable of making accurate predictions or decisions.