Lesson 5: Model Deployment

Prepare for Production
To prepare for production, you need to perform a thorough model analysis for fairness, conduct data quality and model performance checks, implement automation for efficiency, clean up the project and ensure it is production-ready, and package the model for deployment.

Model Analysis and Fairness
Before you deploy a model to production, it is important to perform model analysis to ensure that the model is fair, reliable, and aligned with business goals. Model analysis allows you to answer questions such as:
- How does the model treat individuals from different groups?
- In which areas does the model perform well or poorly?
- What are the most influential features in predicting the outcomes?
- How is the model making predictions?
- How does the model behave under varied conditions?
- Does the model meet legal, ethical, and organizational regulations and standards?
Subpopulation analysis: subpoplation analysis examines how a model performs on specific subsets of the data, compared to its overall performance on the entire dataset. These subsets, or subpopulations, could be based on factors like demographics (age, gender, race), geographic location, or other relevant features. The model may be biased if its performance across subpopulations varies significantly. If the model is not performing similarly across subpopulations, you can further investigate why this is happening, such as checking for data imbalances. You may need to train separate models for subpopulations with poor model performance.
Explainability: Explainability increases the model’s trustworthiness and transparency. Since models could be viewed as black boxes, stakeholders are very interested in understanding how the model is making predictions or decisions. Explainability provides information about the model’s inner workings, helping users and stakeholders to comprehend why a model reached a particular outcome. Explainability is especially important in high-stakes fields like healthcare or finance. Common techniques for achieving explainability includes visualizing feature importance. Features with the highest scores are most influential in predicting the outcomes.
What-if-analysis: What if analysis can allow you to simulate how the model will behave under different conditions. During what-if analysis, you change the values of input features or model parameters and observe how those changes impact the model’s predictions. Sensitivity analysis and model stress test are special types of what-if analysis that allow you to assess the model’s stability and robustness under varied conditions.
Ethical and Responsible AI: Ensure that the model meets specific legal, ethical, and organizational regulations such as:
- data privacy laws (e.g., General Data Protection Regulation or GDPR),
- industry-specific regulations (e.g., Health Insurance Portability and Accountability Act or HIPAA for healthcare)
- internal company policies and guidelines.
Make sure that personal or sensitive data is not used for model training or is handled according to relevant privacy laws and security standards. Make sure the model is transparent, fair and does not discriminate or disproportionately harm or benefit certain groups (e.g., based on gender, race, or socioeconomic status).
Data Quality Checks
There is a popular saying, “garbage in, garbage out,” which also applies when building machine learning models. The accuracy of the model depends on the quality of the data used to train it. Poor data quality can lead to inaccurate predictions and biased results. Data quality checks are essential to ensure that the data used to train and evaluate machine learning models is accurate, complete, consistent, and reliable.
These checks involve identifying and addressing issues such as missing values, duplicate entries, incorrect data types, outliers, and inconsistent formatting. You can also check whether the distribution of variables in the dataset meets certain criteria based on threshold descriptive statistics. High-quality data is crucial for building robust models. By performing comprehensive data quality checks, organizations can improve model performance, increase the reliability of results, and minimize the risk of errors during deployment.
Model Performance Checks
Model performance checks involve evaluating how well a machine learning model is performing on an evaluation dataset to ensure it meets the desired objectives. Performance metrics for classification models, such as accuracy, precision, recall, F1 score, and AUC-ROC, or MSE, RMSE, and R-squared for regression models, can be used to assess the model’s performance.
Regular performance checks on new evaluation datasets are essential for monitoring the model’s effectiveness in production, ensuring it consistently delivers reliable and accurate results over time. Model performance checks also allow you to monitor for performance drift. Similarly, data input drift checks can be set up to monitor changes in input data over time, especially if the evaluation data does not have the ground truth.
Automation
In preparation for deployment, automation is necessary for streamlining and accelerating the deployment process, ensuring consistency, and reducing the potential for human error. You can automate tasks such:
- refreshing datasets
- data quality checks
- model performance checks
- model retraining
- model packaging
- model deployment
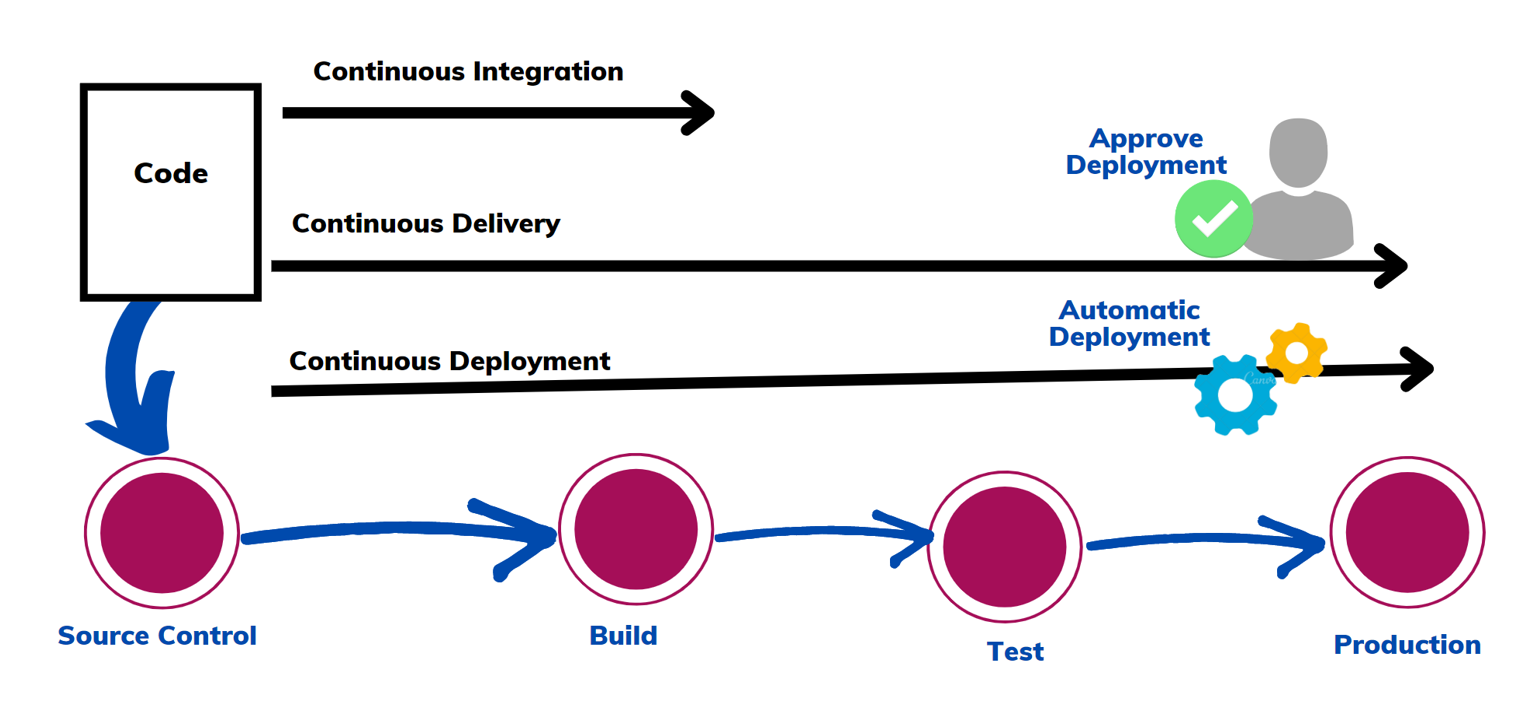
Automation also involves creating automated pipelines for model training and versioning, as well as setting up continuous integration and continuous delivery (CI/CD) processes for smooth and reliable updates. Automation allows you to monitor model performance and input data drift post-deployment, enabling model retraining when drift occurs without manual intervention. Automation ensures that the model is continuously maintained and optimized for real-world performance. A typical CI/CD pipeline is as shown on this diagram below.
Model Packaging
The model needs to be packaged before deploying the packaged model from the development environment to the production environment. Model packaging involves organizing the model it into a format that can be easily integrated into production systems. This involves encapsulating the model along with its dependencies, configuration files, and any necessary libraries, into a portable and versioned package.
The goal is to ensure that the model can be reliably deployed across different environments, such as cloud platforms, on-premises servers, or edge devices, without compatibility issues. Packaging the model into formats such as Docker images, REST APIs, or cloud-specific models (e.g., TensorFlow SavedModel) enables scalability and simplifies the management of updates.
Proper model packaging helps streamline the deployment process, ensures reproducibility, and allows for efficient version control and rollback if necessary. Models packaged as an API service are used for real-time predictions. Batch deployment allow data to be processed in batches periodically (daily, weekly, monthly, etc) as needed. Batch deployment is suitable for scenarios where instant feedback is not required upon collecting the data to score.
Deployment
Deployment is the step in the machine learning lifecycle, where the trained and packaged model is integrated into a production environment to make real-time predictions or batch processing. Real -time API deployment allows the model to be deployed as an API service so that users can access and interact with the model through an API. In real-time API deployment, the model is deployed as an API service that processes individual requests immediately as they are made. Real-time API deployment are suitable for applications where immediate feedback is required, such as personalized recommendations, fraud detection, or autonomous systems that need to act instantly based on live data.
The deployed model is then monitored and maintained in production. Monitoring ensures the performance of the model is not drifting over time while maintenance ensures the model remains functional. Maintenance may include retraining the model with updated data, or addressing any performance issues that arise.
Summary
You need to prepare your ML project before you deploy it to production. Preparing for production involves ensuring your machine learning model meets fairness, data quality, and performance standards. This includes conducting thorough model analysis for bias, explainability, and regulatory compliance, performing data quality checks, and ensuring automation for efficiency. Additionally, the model must be properly packaged for deployment, ensuring compatibility and ease of integration into production systems.
Deployment can be done through batch processing or real-time API services. Real-time deployment processes individual requests instantly, suitable for applications needing immediate feedback. Ongoing monitoring and maintenance are critical post-deployment, ensuring the model’s effectiveness and timely retraining to address performance drift or changes in input data.