Lesson 1: Introduction to Data Science

What is Data Science?
Data science is an interdisciplinary field that uses scientific methods, algorithms, and tools from other fields such as statistics and computing to extract knowledge and insights from data for decision making. Data science is a systematic process of extracting meaning from data.

Data science involves data collection and preparation, exploratory analysis, model development, evaluation, and deployment. It also includes interpreting, communicating, and consuming project results, as well as extracting valuable insights to support decision-making.
The Data Science or Machine Learning Lifecycle
This diagram below illustrates the full lifecycle and high-level workflow of a data science or machine learning project.
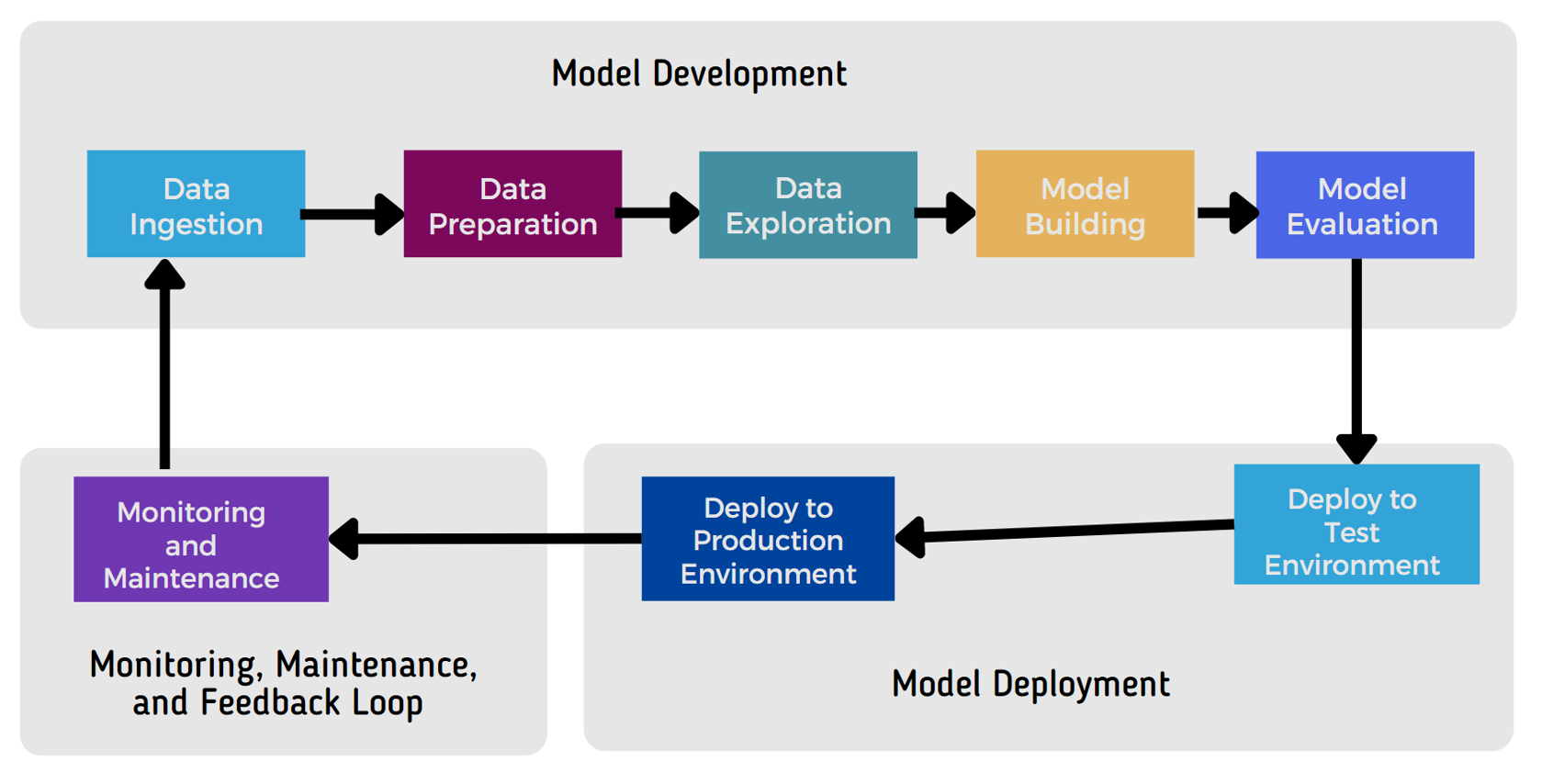
The lifecycle above, also known as the MLOps lifecycle, automates ML model development, deployment, monitoring, and maintenance using DevOps principles.
Analytics and AI/ML Projects
Data science projects generally fall into two main categories: analytics and ML/AI projects. Analytics projects focus on exploring, transforming, aggregating, and interpreting data without the need to train or use machine learning models. In contrast, ML/AI projects generally focus on training and deploying machine learning models from scratch or using pre-trained models to solve problems, make predictions, or support decision-making.
Though the lifecycle illustrated above is more specific to machine learning projects, other types of data science projects could follow a similar process. For instance, an analytics project focused on building a dashboard for business users could be developed, deployed, monitored, and maintained. Likewise, an AI project using a pre-trained large language model (LLM) to extract structured data from PDFs could also go through development, deployment, monitoring, and ongoing maintenance.
Most data scientist focus only on the development aspect of data science projects. However, the lifecycle of an end-to-end data science project spans across development to deployment, maintenance and monitoring. Implementing an end-to-end data science project usually needs a collaboration from data professionals across various role.
Data Teams

The followings data professionals are usually involved in the data science lifecycle:
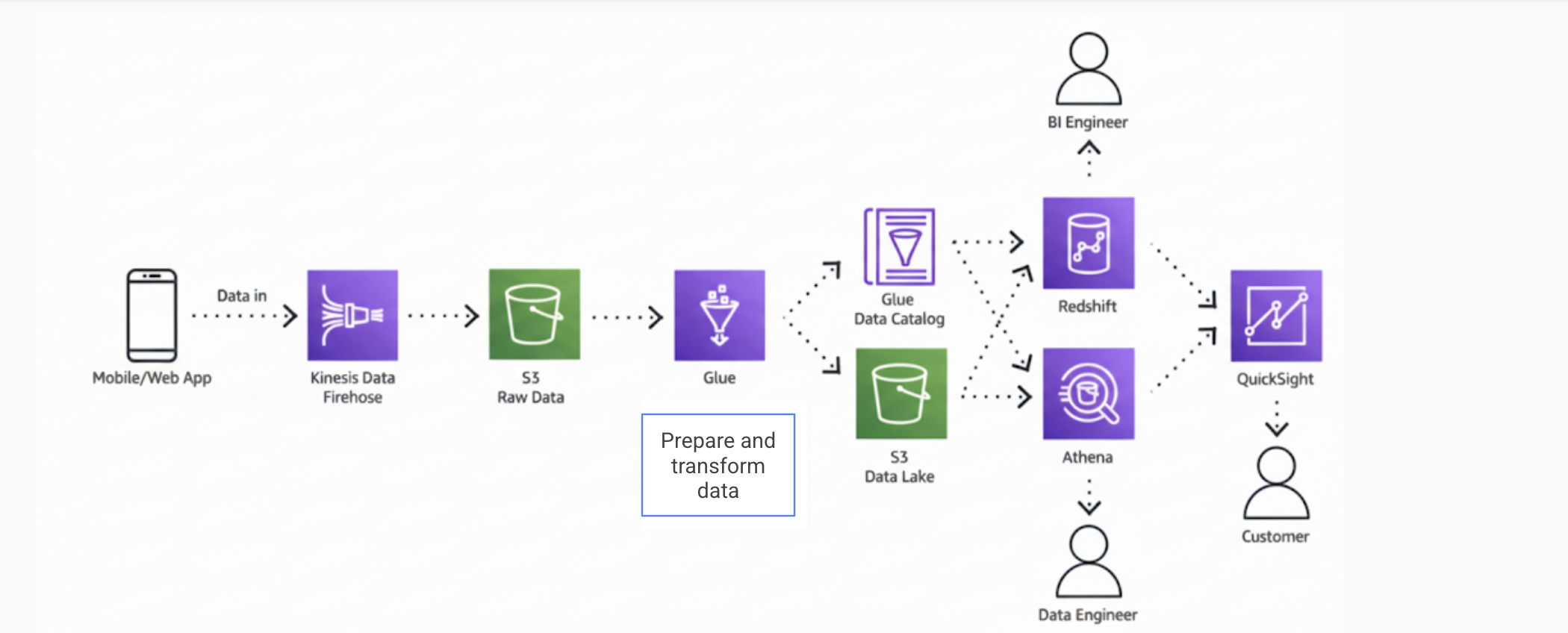
- Data Engineer: A Data Engineer designs and manages data infrastructure, builds ETL pipelines, and ensures data is accessible for analysis. They extract data from various sources, transform it for usability, and load it into systems like data warehouses. Below is an example of a data pipeline — specifically, a data lake architecture in AWS — built to collect, transform, and store data for use by BI and ML tools.
Data Analyst: A Data Analyst transform data into data outputs such as summary tables, reports or dashboards that provide actionable insights for decision making.
Data Scientist A Data Scientist prepares and explores data to build predictive models and runs experiments to optimize performance. A Data Scientist may also work on analytical projects without modeling: for example, early in my career as a Data Scientist, I developed a Python application that automatically extracted Tableau dashboards and emailed them as images to department managers.
Machine Learning Engineer: ML Engineers package and deploy machine learning models in a reliable, scalable, and automated way. They set up systems to monitor performance, trigger retraining when needed, and auto-deploy improved models. In some cases, Infrastructure or IT Engineers assist with deployment.
Understanding Data Scientist Specializations
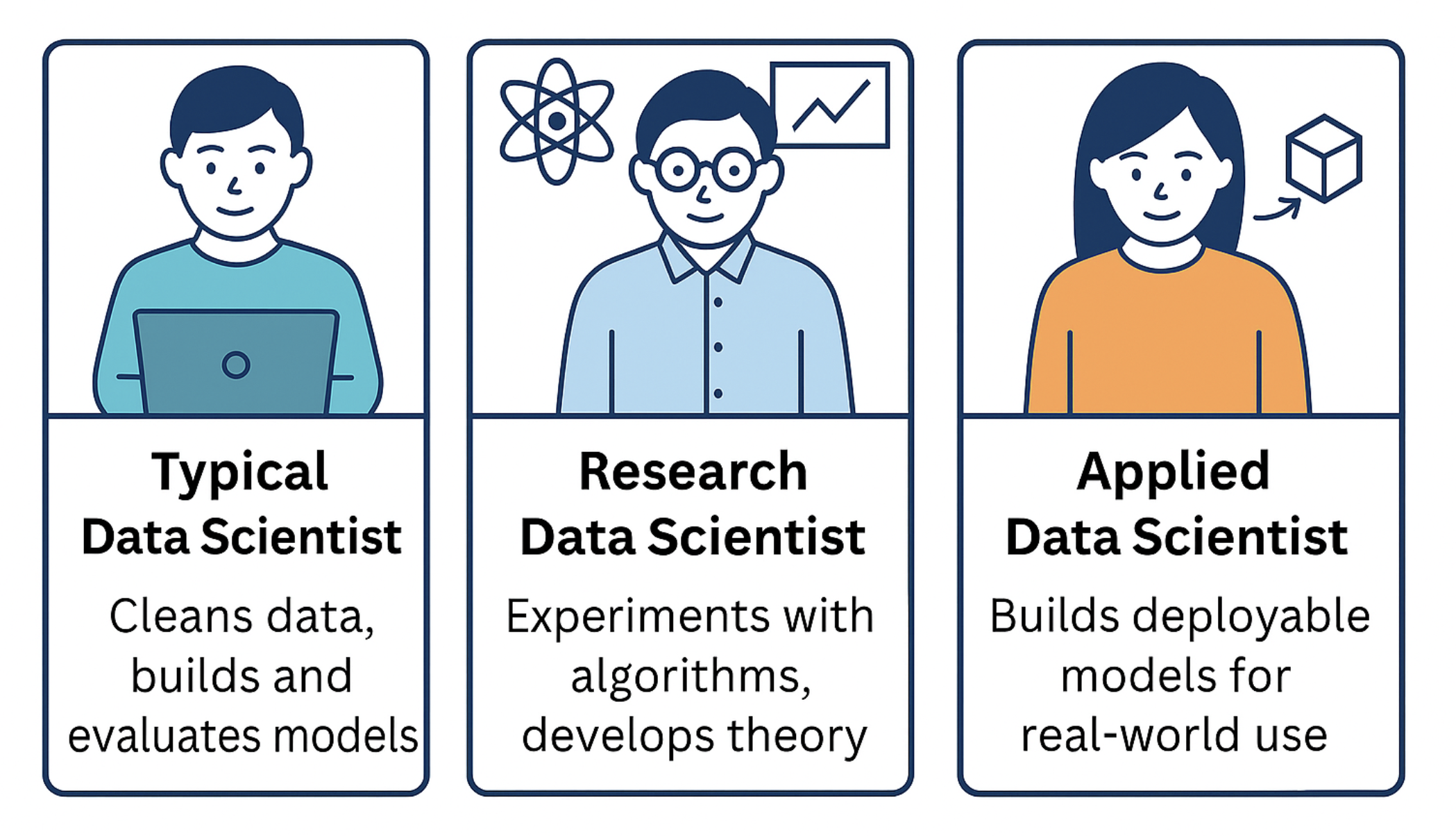
A typical Data Scientist handles data cleaning, model building, and evaluation. They can grow into “full-stack” data scientist by gaining skills in deploying, monitoring, and maintaining models in production. Building these capabilities is key to managing the full data science or machine learning project lifecycle.
Research Data Scientists focus on algorithm experimentation and theoretical model development. They often work in academic or R & D settings. Applied Data Scientists build production-ready models to solve real-world problems. Applied data scientists should develop deployment skills unless supported by an ML deployment team.
Machine Learning Tools
Machine learning frameworks such as MLflow and Kubeflow allow you to create data science or ML pipelines and manage the machine learning lifecycle. Cloud Platforms services such as Amazon SageMaker, Google Vertex AI and Azure Machine learning can also be used to develop, operationalize, monitor, and maintain machine learning models. Additionally, popular frameworks for building machine learning models include TensorFlow, PyTorch, Scikit-learn, Keras, and XGBoost.
Summary
Data science is an interdisciplinary field that uses scientific methods, algorithms, and tools from areas like statistics and computing to extract insights from data for decision-making. A data science project undergoes various phases including data collection, data preparation, data exploration, model development, and evaluation, model deployment, monitoring and maintenance.
Key roles in data science teams include data engineers, data analysts, data scientists, and machine learning engineers. Data engineers handle infrastructure, analysts generate insights, scientists build models, and ML engineers deploy and maintain models. The MLOps lifecycle focuses on efficient development, deployment, monitoring and maintenance of machine learning models using tools like MLflow, Kubeflow, and cloud platforms such as Amazon SageMaker and Azure Machine Learning.